
SPOILER ALERT!
How bad blocks are generated, and what signifies does SSD use to discover and manage bad blocks, what complications exist in the poor block management strategy recommended by the manufacturer, what type of management techniques will probably be greater, a
Overview
The poor block management style notion is connected to SSD reliability and efficiency. Some NandFlash vendors' bad block management practices may not be quite reasonable. When solution design, if some abnormal circumstances will not be thought of sufficient, it will often lead to some unexpected negative blocks.
One example is, immediately after testing quite a few unique most important control SSDs, Bingge located that the issue of newly added negative blocks resulting from abnormal energy failure is very typical. Looking for 'abnormal energy failure produces bad blocks' or comparable keyword phrases having a search engine The issue is just not only within the testing procedure, you will find also quite a few problems that truly happen towards the end user.
Who will handle the negative blocks
For the master devoid of a unique flash file method, the bad blocks is usually managed by the firmware with the SSD controller. For the unique flash file technique, the negative blocks may be managed by the special flash file program or Driver.
Undesirable blocks (BadBlock) are divided into 3 forms:
1. Ex-factory terrible blocks, or initial poor blocks, which is, blocks that don't meet the manufacturer's requirements or fail to meet the manufacturer's published requirements at the time of shipment, have been marked as undesirable blocks by the manufacturer at the factory; Some cannot be Erase;
two. New negative blocks or bad blocks caused by wear for the duration of use;
3. Fake bad blocks that are misjudged by the main control as a result of abnormal energy failure, etc .;
Not all of the newly added poor blocks are brought on by wear. If the SSD doesn't have an abnormal power-off protection function, the abnormal power-off may well bring about the primary manage to misjudge the terrible blocks or create new ones. Without the need of abnormal power-off protection, in the event the Lowerpage has been successfully programmed, in addition to a sudden power failure throughout the Upperpage programming course of action, it'll inevitably cause information transmission errors within the Lowerpage. If the number of data errors exceeds the SSDECC error correction capability, then it will be An error happens through reading, as well as the block are going to be judged as 'BadBlock' by the master and marked in the badblocktable.
Several of the newly added negative blocks can be Erase, and after the newly added terrible blocks are erased, re-reading, reading and erasing the information may perhaps not trigger errors once again, due to the fact the error can also be associated for the pattern of your written data, use a specific pattern If one thing goes wrong, it might not be incorrect to modify a different pattern.
The ratio of factory negative blocks inside the whole Device
I've consulted many original NandFlash companies and gave a more common statement: the ratio of bad blocks in the factory does not exceed 2%, and the manufacturer will leave a aspect of your margin to make sure that even when the maximum number of P / E promised by the manufacturer is reached, There is nevertheless a bad block price of no additional than 2%. It seems that it is not a simple job to assure 2%. The negative block price when Bingge got a new sample exceeded 2%, the actual test was 2.55%
Process for figuring out undesirable blocks
1. Judgment method with the factory bad blocks
The scanning of poor blocks generally scans no matter if the byte corresponding to the address specified by the manufacturer has the FFh flag, and if there's no FFh, it truly is a undesirable block.
The place from the undesirable block identification is roughly precisely the same for every manufacturer. For SLC and MLC, the place is unique. Take Micron as an instance:
1.1 For the SLC of small pages (528Byte), does the sixth Byte within the sparearea of the first page of each block have the FFh flag, if not, it is actually a negative block;
1.two For SLCs with significant pages (greater than or equal to 2112 Bytes), do the initial and sixth Bytes of the Sparearea of the 1st web page of each and every Block have the FFh flag, if not, it's a bad block;
1.three For MLC, the factory terrible blocks are scanned by scanning the very first page along with the last web page of your very first and second Bytes of every block to see when the initially or second Byte may be the 0xFF flag, that is 0xFF, that is so quickly, there's no 0xFF It is a terrible block.
To borrow a image from Hynixdatasheet to illustrate:
What data is inside the bad block? All 0s or all 1s? The results observed by Bingge's test are as follows. Certainly, this may perhaps not be the truth. The factory poor blocks may be true, but it is just not necessary to add new negative blocks, otherwise it's not impossible to hide information by means of 'bad blocks'
Can the factory poor blocks be erased
Some are 'can' erased, and some are prohibited by the manufacturer. The so-called 'can' erase only means that the poor block identification might be changed by sending an erase command, instead of suggesting that negative blocks may be applied.
https://www.pcworld.com/ recommends to not erase the negative block. After the undesirable block flag is erased, it cannot be 'recovered'. Writing data on the poor block is risky.
2. Inside the course of action of applying, the judgment system of newly added negative blocks
The newly added poor block is to judge irrespective of whether the operation of NandFlash is effective via the feedback outcome with the status register. When the System or Erase, when the status register feedback is fail, the SSD key handle will list the block as a negative block.
Particularly:
2.1. Error when executing erase command;
two.two. Error when executing write command;
2.3. An error occurs when the read command is executed; when the study command is executed, if the quantity of bit errors exceeds the error correction capability in the ECC, the block will probably be judged as a terrible block.
Undesirable block management approach
Undesirable blocks are managed by building and updating the terrible block table (BadBlockTable: BBT). There is certainly no uniform specification and practice for the negative block table. Some engineers use a table to handle the factory terrible blocks and newly added undesirable blocks, some engineers will handle the two tables separately, and a few engineers will treat the initial bad blocks as separate Table, factory terrible blocks plus new negative blocks as a different table.
For the content material on the bad block table, the expression just isn't constant, and some will be expressed additional roughly, as an example: use 0 to indicate rapidly, use 1 to indicate poor blocks or vice versa. Some engineers will use a much more detailed description, like: 00 for poor blocks in the factory, 01 for negative blocks when Plan fails, 10 for negative blocks when Study fails, and 11 for bad blocks when Erase fails.
The negative block table is typically saved within a separate location (eg Block0, page0 and Block1, page1). It's more efficient to study BBT straight immediately after each power-on. Thinking of that NandFlash itself will also be damaged, it may bring about the loss of BBT Therefore, BBT is usually utilised for backup processing. The number of backups is various for every single dwelling. A lot of people back up 2 and other folks back up. Normally, you could make use of the probability theory voting system to calculate, regardless of what, at least Extra than 2 copies.
Undesirable block management methods frequently contain: poor block skip method and negative block replacement strategy;
Poor block skip technique
1. For the initial bad block, the bad block skip will skip the corresponding terrible block by way of BBT and straight shop the information in the next great block.
two. For the newly added bad block, update the negative block to BBT, transfer the valid information in the bad block to the next great block, and skip directly when doing the corresponding Study, System or Erse within the future This negative block.
Bad block replacement tactic (suggested by a NandFlash vendor)
Negative block replacement refers to replacing bad blocks generated in the course of use with fantastic blocks in the reserved region. Suppose that throughout the plan, the nth page has an error, then beneath the undesirable block replacement tactic, the data in page0 to page (n-1) will probably be copied for the exact same position from the free of charge Block (eg BlockD) inside the reserved region, Then write the data of the nth web page in the information register for the pagen in BlockD.
The manufacturer's advised approach would be to divide the complete data area into two parts. 1 part could be the user-visible area, that is utilised for regular data operations by the user, plus the other portion is usually a spare region specially prepared for replacing the undesirable block, that is employed to store the data for replacing the undesirable block and Save the negative block table, the proportion of the spare area is 2% from the complete capacity.
When a negative block is generated, FTL will remap the BadBlock address for the very good block address in the reserved region, in place of straight skipping the terrible block towards the subsequent good block. Before each write operation towards the logical address, which physical address will probably be calculated 1st You'll be able to write which addresses are undesirable blocks, and if it is actually a negative block, create the information to the address in the corresponding reserved location.
Brother Bing did not see any suggestion about irrespective of whether 2% of your reserved region need to be included inside the OP location or an additional region, nor did he see a description of regardless of whether the 2% on the reserved region was dynamic or static, and the joining was an independent region And it is actually a static area, then this strategy will have the following disadvantages:
1. Directly reserve 2% with the region for undesirable block replacement, that will minimize the obtainable capacity and waste space. At the same time, resulting from the modest number of available blocks, the average quantity of readily available poor wear is accelerated; two. Assuming that the out there region has a lot more poor blocks At 2%, it indicates that all of the reserved regions are replaced, and also the bad blocks generated is not going to be processed, as well as the SSD will face the finish of life.
Negative block replacement tactic (the practice of some SSD suppliers)
In fact, inside the genuine product design and style, it really is rarely seen that a 2% ratio is reserved as a undesirable block replacement area. Normally, the OP (OverProvison) area freeblock will likely be applied to replace the new addition throughout the use approach. For negative blocks, take garbage collection as an example. When transcend pen drive 8gb repair tool is operating, first move the valid web page information in the Block that needs to be recovered for the freeBlock, after which carry out Erase operation on this Block. Assume that the Erase status register reports that Erase failed. The bad block management mechanism will update this Block address towards the new terrible block list, in the exact same time, write the valid data pages in the terrible block towards the FreeBlock in the OP region, update the terrible block management table, the next time you write information , Straight skip the undesirable block for the subsequent offered block.
Unique producers have distinctive OP sizes, unique application scenarios, unique reliability specifications, and distinct OP sizes. There's a trade-off connection in between OP and stability. The larger the OP, the extra garbage is written in the method of continuous writing. The larger the reclaimed no cost space, the far more steady the efficiency and also the smoother the functionality curve. Conversely, the smaller the OP, the worse the efficiency stability. Certainly, the larger the user's accessible space, the bigger the out there space suggests the additional price low.
Typically speaking, OP might be set to 5% -50%, 7% of OP can be a widespread ratio, unlike the 2% fixed block recommended by the manufacturer, 7% just isn't a fixed block to do OP, Instead, it is dynamically distributed in all Blocks, which can be more conducive to wear-leveling strategies.
The troubles of SSD repair
For most SSD companies who do not have the master manage technologies, in the event the product is repaired, the usual practice is usually to replace the faulty device and restart the mass production operation. At this time, the new bad block list is going to be lost, along with the new poor block list might be lost. This indicates that you'll find already poor blocks inside the NandFlash which have not been replaced. The operating system or sensitive information may possibly be written to the terrible block region, which could result in the user's operating program to crash. Even for any manufacturer having a master handle, regardless of whether it's going to save a list of existing poor blocks for the user is determined by the attitude of your user facing the manufacturer.
Whether bad block production will impact the read and write speed and stability of SSD
Factory terrible blocks might be separated on the bitline, so it is going to not impact the erase and create speed of other blocks. Having said that, if there are actually adequate new negative blocks in the entire SSD, the out there blocks with the complete disk will probably be reduced, which will lead to an increase in the number of garbage collections. The reduction in OP capacity will seriously impact the efficiency of garbage collection. As a result, rising the amount of terrible blocks to a specific level will impact the performance stability with the SSD, especially when the SSD is continuously written. For the reason that the method performs garbage collection, it can cause In the event the performance drops, the SSD overall performance curve will fluctuate considerably.
Bing brother personal WeChat, welcome to exchange:
The poor block management style notion is connected to SSD reliability and efficiency. Some NandFlash vendors' bad block management practices may not be quite reasonable. When solution design, if some abnormal circumstances will not be thought of sufficient, it will often lead to some unexpected negative blocks.
One example is, immediately after testing quite a few unique most important control SSDs, Bingge located that the issue of newly added negative blocks resulting from abnormal energy failure is very typical. Looking for 'abnormal energy failure produces bad blocks' or comparable keyword phrases having a search engine The issue is just not only within the testing procedure, you will find also quite a few problems that truly happen towards the end user.
Who will handle the negative blocks
For the master devoid of a unique flash file method, the bad blocks is usually managed by the firmware with the SSD controller. For the unique flash file technique, the negative blocks may be managed by the special flash file program or Driver.
Undesirable blocks (BadBlock) are divided into 3 forms:
1. Ex-factory terrible blocks, or initial poor blocks, which is, blocks that don't meet the manufacturer's requirements or fail to meet the manufacturer's published requirements at the time of shipment, have been marked as undesirable blocks by the manufacturer at the factory; Some cannot be Erase;
two. New negative blocks or bad blocks caused by wear for the duration of use;
3. Fake bad blocks that are misjudged by the main control as a result of abnormal energy failure, etc .;
Not all of the newly added poor blocks are brought on by wear. If the SSD doesn't have an abnormal power-off protection function, the abnormal power-off may well bring about the primary manage to misjudge the terrible blocks or create new ones. Without the need of abnormal power-off protection, in the event the Lowerpage has been successfully programmed, in addition to a sudden power failure throughout the Upperpage programming course of action, it'll inevitably cause information transmission errors within the Lowerpage. If the number of data errors exceeds the SSDECC error correction capability, then it will be An error happens through reading, as well as the block are going to be judged as 'BadBlock' by the master and marked in the badblocktable.
Several of the newly added negative blocks can be Erase, and after the newly added terrible blocks are erased, re-reading, reading and erasing the information may perhaps not trigger errors once again, due to the fact the error can also be associated for the pattern of your written data, use a specific pattern If one thing goes wrong, it might not be incorrect to modify a different pattern.
The ratio of factory negative blocks inside the whole Device
I've consulted many original NandFlash companies and gave a more common statement: the ratio of bad blocks in the factory does not exceed 2%, and the manufacturer will leave a aspect of your margin to make sure that even when the maximum number of P / E promised by the manufacturer is reached, There is nevertheless a bad block price of no additional than 2%. It seems that it is not a simple job to assure 2%. The negative block price when Bingge got a new sample exceeded 2%, the actual test was 2.55%
Process for figuring out undesirable blocks
1. Judgment method with the factory bad blocks
The scanning of poor blocks generally scans no matter if the byte corresponding to the address specified by the manufacturer has the FFh flag, and if there's no FFh, it truly is a undesirable block.
The place from the undesirable block identification is roughly precisely the same for every manufacturer. For SLC and MLC, the place is unique. Take Micron as an instance:
1.1 For the SLC of small pages (528Byte), does the sixth Byte within the sparearea of the first page of each block have the FFh flag, if not, it is actually a negative block;
1.two For SLCs with significant pages (greater than or equal to 2112 Bytes), do the initial and sixth Bytes of the Sparearea of the 1st web page of each and every Block have the FFh flag, if not, it's a bad block;
1.three For MLC, the factory terrible blocks are scanned by scanning the very first page along with the last web page of your very first and second Bytes of every block to see when the initially or second Byte may be the 0xFF flag, that is 0xFF, that is so quickly, there's no 0xFF It is a terrible block.
To borrow a image from Hynixdatasheet to illustrate:
What data is inside the bad block? All 0s or all 1s? The results observed by Bingge's test are as follows. Certainly, this may perhaps not be the truth. The factory poor blocks may be true, but it is just not necessary to add new negative blocks, otherwise it's not impossible to hide information by means of 'bad blocks'
Can the factory poor blocks be erased
Some are 'can' erased, and some are prohibited by the manufacturer. The so-called 'can' erase only means that the poor block identification might be changed by sending an erase command, instead of suggesting that negative blocks may be applied.
https://www.pcworld.com/ recommends to not erase the negative block. After the undesirable block flag is erased, it cannot be 'recovered'. Writing data on the poor block is risky.
2. Inside the course of action of applying, the judgment system of newly added negative blocks
The newly added poor block is to judge irrespective of whether the operation of NandFlash is effective via the feedback outcome with the status register. When the System or Erase, when the status register feedback is fail, the SSD key handle will list the block as a negative block.
Particularly:
2.1. Error when executing erase command;
two.two. Error when executing write command;
2.3. An error occurs when the read command is executed; when the study command is executed, if the quantity of bit errors exceeds the error correction capability in the ECC, the block will probably be judged as a terrible block.
Undesirable block management approach
Undesirable blocks are managed by building and updating the terrible block table (BadBlockTable: BBT). There is certainly no uniform specification and practice for the negative block table. Some engineers use a table to handle the factory terrible blocks and newly added undesirable blocks, some engineers will handle the two tables separately, and a few engineers will treat the initial bad blocks as separate Table, factory terrible blocks plus new negative blocks as a different table.
For the content material on the bad block table, the expression just isn't constant, and some will be expressed additional roughly, as an example: use 0 to indicate rapidly, use 1 to indicate poor blocks or vice versa. Some engineers will use a much more detailed description, like: 00 for poor blocks in the factory, 01 for negative blocks when Plan fails, 10 for negative blocks when Study fails, and 11 for bad blocks when Erase fails.
The negative block table is typically saved within a separate location (eg Block0, page0 and Block1, page1). It's more efficient to study BBT straight immediately after each power-on. Thinking of that NandFlash itself will also be damaged, it may bring about the loss of BBT Therefore, BBT is usually utilised for backup processing. The number of backups is various for every single dwelling. A lot of people back up 2 and other folks back up. Normally, you could make use of the probability theory voting system to calculate, regardless of what, at least Extra than 2 copies.
Undesirable block management methods frequently contain: poor block skip method and negative block replacement strategy;
Poor block skip technique
1. For the initial bad block, the bad block skip will skip the corresponding terrible block by way of BBT and straight shop the information in the next great block.
two. For the newly added bad block, update the negative block to BBT, transfer the valid information in the bad block to the next great block, and skip directly when doing the corresponding Study, System or Erse within the future This negative block.
Bad block replacement tactic (suggested by a NandFlash vendor)
Negative block replacement refers to replacing bad blocks generated in the course of use with fantastic blocks in the reserved region. Suppose that throughout the plan, the nth page has an error, then beneath the undesirable block replacement tactic, the data in page0 to page (n-1) will probably be copied for the exact same position from the free of charge Block (eg BlockD) inside the reserved region, Then write the data of the nth web page in the information register for the pagen in BlockD.
The manufacturer's advised approach would be to divide the complete data area into two parts. 1 part could be the user-visible area, that is utilised for regular data operations by the user, plus the other portion is usually a spare region specially prepared for replacing the undesirable block, that is employed to store the data for replacing the undesirable block and Save the negative block table, the proportion of the spare area is 2% from the complete capacity.
When a negative block is generated, FTL will remap the BadBlock address for the very good block address in the reserved region, in place of straight skipping the terrible block towards the subsequent good block. Before each write operation towards the logical address, which physical address will probably be calculated 1st You'll be able to write which addresses are undesirable blocks, and if it is actually a negative block, create the information to the address in the corresponding reserved location.
Brother Bing did not see any suggestion about irrespective of whether 2% of your reserved region need to be included inside the OP location or an additional region, nor did he see a description of regardless of whether the 2% on the reserved region was dynamic or static, and the joining was an independent region And it is actually a static area, then this strategy will have the following disadvantages:
1. Directly reserve 2% with the region for undesirable block replacement, that will minimize the obtainable capacity and waste space. At the same time, resulting from the modest number of available blocks, the average quantity of readily available poor wear is accelerated; two. Assuming that the out there region has a lot more poor blocks At 2%, it indicates that all of the reserved regions are replaced, and also the bad blocks generated is not going to be processed, as well as the SSD will face the finish of life.
Negative block replacement tactic (the practice of some SSD suppliers)
In fact, inside the genuine product design and style, it really is rarely seen that a 2% ratio is reserved as a undesirable block replacement area. Normally, the OP (OverProvison) area freeblock will likely be applied to replace the new addition throughout the use approach. For negative blocks, take garbage collection as an example. When transcend pen drive 8gb repair tool is operating, first move the valid web page information in the Block that needs to be recovered for the freeBlock, after which carry out Erase operation on this Block. Assume that the Erase status register reports that Erase failed. The bad block management mechanism will update this Block address towards the new terrible block list, in the exact same time, write the valid data pages in the terrible block towards the FreeBlock in the OP region, update the terrible block management table, the next time you write information , Straight skip the undesirable block for the subsequent offered block.
Unique producers have distinctive OP sizes, unique application scenarios, unique reliability specifications, and distinct OP sizes. There's a trade-off connection in between OP and stability. The larger the OP, the extra garbage is written in the method of continuous writing. The larger the reclaimed no cost space, the far more steady the efficiency and also the smoother the functionality curve. Conversely, the smaller the OP, the worse the efficiency stability. Certainly, the larger the user's accessible space, the bigger the out there space suggests the additional price low.
Typically speaking, OP might be set to 5% -50%, 7% of OP can be a widespread ratio, unlike the 2% fixed block recommended by the manufacturer, 7% just isn't a fixed block to do OP, Instead, it is dynamically distributed in all Blocks, which can be more conducive to wear-leveling strategies.
The troubles of SSD repair
For most SSD companies who do not have the master manage technologies, in the event the product is repaired, the usual practice is usually to replace the faulty device and restart the mass production operation. At this time, the new bad block list is going to be lost, along with the new poor block list might be lost. This indicates that you'll find already poor blocks inside the NandFlash which have not been replaced. The operating system or sensitive information may possibly be written to the terrible block region, which could result in the user's operating program to crash. Even for any manufacturer having a master handle, regardless of whether it's going to save a list of existing poor blocks for the user is determined by the attitude of your user facing the manufacturer.
Whether bad block production will impact the read and write speed and stability of SSD
Factory terrible blocks might be separated on the bitline, so it is going to not impact the erase and create speed of other blocks. Having said that, if there are actually adequate new negative blocks in the entire SSD, the out there blocks with the complete disk will probably be reduced, which will lead to an increase in the number of garbage collections. The reduction in OP capacity will seriously impact the efficiency of garbage collection. As a result, rising the amount of terrible blocks to a specific level will impact the performance stability with the SSD, especially when the SSD is continuously written. For the reason that the method performs garbage collection, it can cause In the event the performance drops, the SSD overall performance curve will fluctuate considerably.
Bing brother personal WeChat, welcome to exchange:

SPOILER ALERT!
Retrieve accidentally deleted files without software
I accidentally deleted the essential factors. What must I do? Let's see! 1. official site 'Start-Run, then enter
The following content material desires reply to view
Regedit (open the registry)
2. Expand in order: HEKEY——LOCAL——MACHIME / Application / MICROSOFT / WINDOWS /
CURRENTVERSION / EXPLORER / DESKTOP / nAMESPACE Click 'New' in the left margin, select: 'primary key', name it '645FFO40——5081——101B ---- 9F08——00AA002F954E' and after that the best 'default' main essential Is set to 'Recycle Bin' and after that exit the registry.
3. Restart your computer. Provided that your machine has not run defragmentation. The method is intact. Files may be retrieved at any time.
corrupted sd card video file recovery
The following content material desires reply to view
Regedit (open the registry)
2. Expand in order: HEKEY——LOCAL——MACHIME / Application / MICROSOFT / WINDOWS /
CURRENTVERSION / EXPLORER / DESKTOP / nAMESPACE Click 'New' in the left margin, select: 'primary key', name it '645FFO40——5081——101B ---- 9F08——00AA002F954E' and after that the best 'default' main essential Is set to 'Recycle Bin' and after that exit the registry.
3. Restart your computer. Provided that your machine has not run defragmentation. The method is intact. Files may be retrieved at any time.
corrupted sd card video file recovery

SPOILER ALERT!
Have you ever encountered such a predicament? I use U disk or mobile challenging disk to back up files, but I can't find the U disk at crucial moments, and even encounter the predicament that the mobile really hard disk is broken. At this time, did you su
A blogger, Sausage, shared the explanation why he set aside the mobile really hard disk and utilised NAS as an alternative. Let's check out how the safest storage on earth is created? !
7 factors to inform you why you need to use NAS instead of a mobile challenging disk to back up information. Original: Sausage Squid
1 Far more easy information sharing access and permissions Standard mobile really hard disks cannot be shared by several men and women. If numerous people are essential to utilize them, they're able to only be employed interchangeably, which is pretty troublesome.
Now all you may need to accomplish is throw each of the data into the NAS, and also you can read the files stored inside the NAS at any time through the network, and you can also accurately handle and control the access rights from the NAS.
two Quicker processing speed, the hardware device to improve the mobile difficult disk will not be suitable for accessing and editing at any time, simply because if you accidentally touch the data line, you could interrupt the connection.
Now provided that the animations and films are stored inside the NAS, once you need to watch them, you may share the disk region through the network, it is possible to watch the films directly without the need of downloading, and for the reason that the LAN is read at gigabit speed, the smoothness isn't discounted.
3 Safer data storage, RAID numerous backups The average individual adopts a backup strategy of 'don't place eggs inside the very same basket', put the movie on this difficult drive, and also the data is backed up on another difficult drive, but do you know which tough drive is going to be broken? And from time to time it can even drop the challenging disk if it is left alone, which can be not so handy in management.
By way of NAS, we are able to resolve such issues. The NAS supports RAID information protection, and a few RAID forms permit certainly one of the hard drives to be broken. Regardless of which tough drive is damaged, all information will nonetheless exist. Just buy a brand new challenging drive to produce it back up and let the NAS technique do it for you personally. The difficult disk tends to make up for the vacancy!
four Extra user-friendly management system-DSM regular mobile hard disk only supplies file storage function, and may not do the appropriate data classification, or far more applications.
NAS has changed the function of hard disks for storage only. By bing of example, Synology has developed a dedicated operating technique 'DSM' for NAS, which makes NAS a lot more usable and no longer just difficult disks. Via DSM management, it can be easier To find out the status with the difficult disk, the program can do far more advanced permissions settings.
5 Cross-platform access is simple and handy: mobile phones, tablets, computer systems, TVs are out, if you would like to work with your mobile phone to read files, you have to bring a mobile hard disk or U disk to go out, which can be incredibly cumbersome and unsatisfactory.
By way of NAS-specific APPs, for instance Synology ’s DSfile, you'll be able to even access the files within the NAS from dwelling. To watch motion pictures, you are able to also set up DSvideo on your mobile telephone or Television to access the film library you created. In the event the Tv might be connected towards the Web, you may also match the Xiaomi box or directly play the videos and music in the NAS on the Television, that are difficult areas for the mobile difficult disk.
six Much more convenient sharing approaches, cross-storage comfort applications NAS has been reborn and is no longer a simple server or network shared tough disk, but a convenience application aside from backup and storage.
Take Synology VideoStation as an instance, you'll be able to share the video having a buddy, and let the friend watch your preferred video in line with the hyperlink you supplied. PhotoStation also can share photographs in its personal NAS with good friends, and turn sharing on and off as you like, without having getting limited by the capacity of public cloud albums.
7 Extra outstanding APP: The download and web site setup are all completed. The mobile hard disk is only a tough disk. The challenging disk that could be accessed by means of USB doesn't have other advanced functions. The variability is definitely not like a little server like NAS. widely.
https://en.wikipedia.org/wiki/Software of the positive aspects of NAS is usually to make storage far more intriguing. The storage data is no longer just the transmission of data, but could make great use in the cost-free a part of the really hard disk to perform other factors. Before, some buddies used NAS to setup their own internet sites. Moreover, they could do much more company applications, cloud notebooks, and so on. As a result of these APPs, the functions of NAS are obtaining a lot more and more abundant, no longer just NAS, but a multifunctional server!
The storage ought to be so hassle-free, promptly throw away the prehistoric information storage strategy, and practice the safest storage around the earth with sausage!
7 factors to inform you why you need to use NAS instead of a mobile challenging disk to back up information. Original: Sausage Squid
1 Far more easy information sharing access and permissions Standard mobile really hard disks cannot be shared by several men and women. If numerous people are essential to utilize them, they're able to only be employed interchangeably, which is pretty troublesome.
Now all you may need to accomplish is throw each of the data into the NAS, and also you can read the files stored inside the NAS at any time through the network, and you can also accurately handle and control the access rights from the NAS.
two Quicker processing speed, the hardware device to improve the mobile difficult disk will not be suitable for accessing and editing at any time, simply because if you accidentally touch the data line, you could interrupt the connection.
Now provided that the animations and films are stored inside the NAS, once you need to watch them, you may share the disk region through the network, it is possible to watch the films directly without the need of downloading, and for the reason that the LAN is read at gigabit speed, the smoothness isn't discounted.
3 Safer data storage, RAID numerous backups The average individual adopts a backup strategy of 'don't place eggs inside the very same basket', put the movie on this difficult drive, and also the data is backed up on another difficult drive, but do you know which tough drive is going to be broken? And from time to time it can even drop the challenging disk if it is left alone, which can be not so handy in management.
By way of NAS, we are able to resolve such issues. The NAS supports RAID information protection, and a few RAID forms permit certainly one of the hard drives to be broken. Regardless of which tough drive is damaged, all information will nonetheless exist. Just buy a brand new challenging drive to produce it back up and let the NAS technique do it for you personally. The difficult disk tends to make up for the vacancy!
four Extra user-friendly management system-DSM regular mobile hard disk only supplies file storage function, and may not do the appropriate data classification, or far more applications.
NAS has changed the function of hard disks for storage only. By bing of example, Synology has developed a dedicated operating technique 'DSM' for NAS, which makes NAS a lot more usable and no longer just difficult disks. Via DSM management, it can be easier To find out the status with the difficult disk, the program can do far more advanced permissions settings.
5 Cross-platform access is simple and handy: mobile phones, tablets, computer systems, TVs are out, if you would like to work with your mobile phone to read files, you have to bring a mobile hard disk or U disk to go out, which can be incredibly cumbersome and unsatisfactory.
By way of NAS-specific APPs, for instance Synology ’s DSfile, you'll be able to even access the files within the NAS from dwelling. To watch motion pictures, you are able to also set up DSvideo on your mobile telephone or Television to access the film library you created. In the event the Tv might be connected towards the Web, you may also match the Xiaomi box or directly play the videos and music in the NAS on the Television, that are difficult areas for the mobile difficult disk.
six Much more convenient sharing approaches, cross-storage comfort applications NAS has been reborn and is no longer a simple server or network shared tough disk, but a convenience application aside from backup and storage.
Take Synology VideoStation as an instance, you'll be able to share the video having a buddy, and let the friend watch your preferred video in line with the hyperlink you supplied. PhotoStation also can share photographs in its personal NAS with good friends, and turn sharing on and off as you like, without having getting limited by the capacity of public cloud albums.
7 Extra outstanding APP: The download and web site setup are all completed. The mobile hard disk is only a tough disk. The challenging disk that could be accessed by means of USB doesn't have other advanced functions. The variability is definitely not like a little server like NAS. widely.
https://en.wikipedia.org/wiki/Software of the positive aspects of NAS is usually to make storage far more intriguing. The storage data is no longer just the transmission of data, but could make great use in the cost-free a part of the really hard disk to perform other factors. Before, some buddies used NAS to setup their own internet sites. Moreover, they could do much more company applications, cloud notebooks, and so on. As a result of these APPs, the functions of NAS are obtaining a lot more and more abundant, no longer just NAS, but a multifunctional server!
The storage ought to be so hassle-free, promptly throw away the prehistoric information storage strategy, and practice the safest storage around the earth with sausage!

SPOILER ALERT!
Frequently speaking, the computer is divided into two disks by default. For customers, too handful of disks cannot be distinguished when saving files. Consequently, some customers will use the system of computer partition to solve this difficulty. However
Commonly speaking, when the information in the laptop is just deleted, the files can be retrieved from the recycle bin. Even so, the laptop partition is equivalent to formatting the disk and operating the disk once more. For google , the difficulty factor of data recovery is somewhat massive, and also the difficulty factor is huge, which does not mean that the data cannot be recovered. Frequently speaking, when a pc partition causes data loss, Xiaobian recommends that you initial download successful information recovery software to scan the disk to view in the event you can find the lost data. The distinct operations are as follows:
Demonstration of powerful data recovery software program operation steps are as follows:
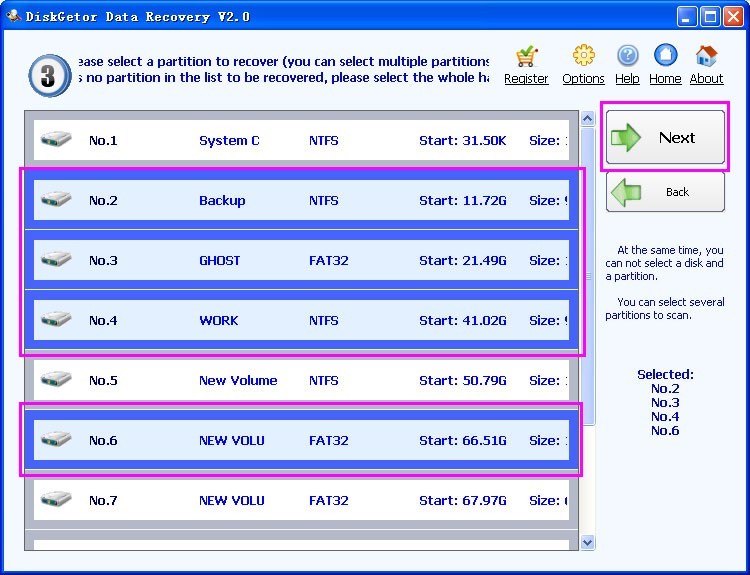
1. formatted sd card micro file recovery and install the efficient data recovery software program, then open the software program, select the corresponding information recovery mode within the function interface to recover the lost files formatted by the mobile tough disk, please click 'Format Recovery'.
2. Soon after choosing the corresponding function, please select the mobile challenging disk partition exactly where you want to restore the file, or expand the difficult disk to choose the folder exactly where the file is situated, click the 'Start Scan' button within the decrease right corner to scan the mobile hard disk, please wait patiently for the file scanning to finish.
three. Right after scanning, please obtain the file to be restored inside the software program interface. The software program offers users using a document and picture preview function. The user can click on the relevant file to preview it. Immediately after obtaining the selected mobile hard disk file to be restored, click Restore.
4. Just after the software switches the interface, please click 'Select Export Directory' to set the storage location in the deleted files with the restored mobile really hard disk. Immediately after the settings are completed, click the 'OK' button to enter the information recovery state.
Demonstration of powerful data recovery software program operation steps are as follows:
1. formatted sd card micro file recovery and install the efficient data recovery software program, then open the software program, select the corresponding information recovery mode within the function interface to recover the lost files formatted by the mobile tough disk, please click 'Format Recovery'.
2. Soon after choosing the corresponding function, please select the mobile challenging disk partition exactly where you want to restore the file, or expand the difficult disk to choose the folder exactly where the file is situated, click the 'Start Scan' button within the decrease right corner to scan the mobile hard disk, please wait patiently for the file scanning to finish.
three. Right after scanning, please obtain the file to be restored inside the software program interface. The software program offers users using a document and picture preview function. The user can click on the relevant file to preview it. Immediately after obtaining the selected mobile hard disk file to be restored, click Restore.
4. Just after the software switches the interface, please click 'Select Export Directory' to set the storage location in the deleted files with the restored mobile really hard disk. Immediately after the settings are completed, click the 'OK' button to enter the information recovery state.

SPOILER ALERT!
When making use of a digital camera, for those who accidentally delete the information on the memory card (for example accidental formatting), it will likely be an enormous blow to you, in particular these valuable, unreproducible lenses, which can not be
Actually, the memory card can also be a kind of data storage. In principle, it can be the identical because the floppy disk and really hard disk. As a result, some disk data recovery tool application can be applied to restore the information in the memory card. Now the CF card and memory stick Experiment with all the subject.
1. Test circumstances
CF card (WINWARD) —128MbSONY original memory stick—32Mb Jinshengyi USB6 in 1 card reader Gigabyte KT4400 motherboard AMD1700 + CPU512MbDDR memory, operating system is WIN2000.
A total of 4 usually employed information recovery softwares had been selected for the experiment. The method is to take a image first, so that you'll find some picture files in the memory card, and after that copy it to a directory as a typical for comparison; then delete the image (or Format in the camera), and after that use several computer software to restore, verify the recovery effect, the comfort of operation, the time applied, and so on.
2. Brief introduction of precise test
2-1, BadCopyproV3.71 Chinese version (size 778Kb)
The installation and registration are regular, you'll be able to use the registration code offered by the download to register, and its operating interface is shown inside the figure under.
Attributes: It could recover data from a number of storage media including floppy disks, CD-ROMs, really hard disks, memory cards, etc. The operation is easy, and also you can start off operating according to the prompts. You are able to opt for the file format when recovering the memory card of the digital camera. The software functions in a complete sector scan mode, after which the file to be restored along with the storage path will have to be chosen prior to the recovered file is officially saved. It could recover all the files on the memory card-the sum on the earlier occasions: As an example, the 128Mb card has 200 photos before, and then formatted, and took an additional 20 images. When the resolution may be the very same prior to and just after, then you can change the final one 20 sheets and 180 sheets (around) in the earlier 200 sheets are restored.
test outcomes:
1. 128MbCF card, formatted after the previous photo, 19 pictures had been taken, deleted and restored, shared 16 minutes, a total of 175 recovered, which includes the final 19, all photographs might be displayed typically.
two. 32Mb memory stick, the last file is 19, 23 files have been restored, two of them can't be displayed typically (the image is only the upper half), and also the shared time is 6 minutes.
All data recovery is stored within the specified folder, and will not be written to the memory card. The recovered file name is: File ###. JPG.
The above approaches are applicable to deleted and formatted memory cards.
2-2 、 EasyRecoveryV6.0 Chinese version
This is a full-featured disk tool application which can execute disk diagnosis, information repair, file repair, mail repair, and so on., and its operating interface is shown within the figure below.
Use the 'Find and restore deleted files' or 'Restore devoid of relying on any file program structure information' (just after formatting the memory card) solution for the memory card. The latter needs to select the information format and scan it rapidly after picking the drive letter The folder around the card (the name will be the identical because the card) along with the file name, file size, and time in it, and then choose the file to become restored to restore. The exceptional function of this computer software is that it runs extremely rapid. Taking SONY32Mb memory stick as an instance, it took only 90 seconds to recover 23 files. The recovered file is SC0 ###. JPG is named and stored inside the specified folder. There are 4 troubles with the recovered files, two are only the upper aspect (exact same as 2-1), and two can't be opened.
2-3 、 PHOTORECOVERYV2.0 Chinese version demo version
This can be a easy and easy-to-use data recovery software program. Its interface is intuitive and straightforward, and the operation might be completed within a handful of actions: initial select the drive letter and the folder exactly where the data is usually to be restored, click Start off to swiftly restore, and it runs The interface is shown below.
The difference using the above software is the fact that in addition, it displays thumbnails synchronously. disappeared sd card disappeared file recovery recovers 23 files in only 1 minute and 55 seconds, and certainly one of them is damaged. Using a 128MbCF card, it took only 6 minutes and ten seconds to restore 175 files (far more than 10 minutes quicker than BadCopypro), and all pictures is usually displayed generally. Nevertheless it is often a pity that the demo version is at the moment utilized and cannot store the recovered data.
The application also visually displays info which include the capacity of your memory card, the partition size, along with the variety of recovered files within the lower left corner with the interface. The recovered information is named 'Image # .JPG'.
2-4 、 AboutmediaRECOVERV2.two.two.4 English version

This is also a graphical interface computer software, the running interface is shown under.
The usage of the software program is similar to PHOTORECOVERY. First choose the drive letter in the memory card as well as the storage folder from the recovery file, and then start out scanning and recovery. It requires a lengthy time and errors. This version cannot be employed commonly.
three. Summary
By way of experiments, it may be noticed that the files inside the memory card is usually entirely recovered immediately after accidental deletion or formatting. The above 4 software can total the recovery operate, plus the functioning approaches are similar, all of which scan the memory card sectors 1st. Just after that, save the recovered files in the designated folder from the difficult disk, and no a lot more files are written to the memory card, so this recovery is secure and will not bring about damage towards the memory card (but BadCopypro computer software demands a lengthy time for you to the card Scan, it really is suggested to make use of significantly less). But the recovery time of every single software program is very diverse. For the 128MbCF card, the lengthy one took 16 minutes along with the quick one particular took six minutes. For Diskgetor damaged sd card camera file recovery , beneath the premise of meeting the needs, you'll want to choose a short-time application as a way to enhance efficiency. For that reason, it is advisable to decide on EasyRecoveryV6.0 Chinese version. If you can register, use PHOTORECOVERYV2.0 is also a fantastic choice; and for long-term memory cards , You could use BadCopyproV3.71 Chinese version to execute a sector scan to view if there is certainly a terrible sector, and also you know it.
The above software program, the compatibility of numerous storage is limited for the conditions, only the CF card and SONY memory stick are tested, along with other memory cards for instance SD, SM, MMC, and so forth. are not tested. It really is advised that those who own these memory cards test and report the outcomes .
In the scanning and recovery of the two cards, if the good quality on the card is no challenge, the recovery is usually standard, and if the card is defective, the software may not be capable of repair, such as two files in the 32Mb memory stick, the software program Only half of the photos are displayed for recovery.
Reference address for downloading the above software program:
EasyRecoveryV6.0 Chinese version http://www.skycn.com/soft/2070.html
PHOTORECOVERYV2.0 http://www.ttdown.com/SoftView/SoftView_12855.html
BadCopyproV3.71 Chinese version http://www.gupin.com/soft/358.htm and
http://www.ttdown.com/SoftView/SoftView_3853.html
mediaRECOVERV2.two.2.4 English version http://www.ttdown.com/SoftView/SoftView_17097.html and http://www.onlinedown.net/soft/20285.htm
Every single day site: http: //www.ttdown.com's graphic image bar can come across many software
1. 'DriveRescue'
Download: www.onlinedown.net/soft/7799.htm
Function: DriveRescue is definitely an great and cost-free disk information rescue program, it can restore information deleted or lost on the drive (for instance difficult disk), even if the partition table has been lost or the hard disk has been quickly formatted or encountered system crashes, Retrieve vital file program facts of your drive such as partition table, boot record, FAT, file / directory records, etc. Not surprisingly, it can do practically nothing about physically broken challenging drives. DriveRescue supports FAT12 / 16/32 partitions, Windows complete range of operating systems and dual tough drives.
two. 'FinalDataOEMv2.0 Simplified Chinese Official Version' supports memory cards with more than 512MB http://www.jz5u.com/Codelist/Catalog160/1978.html
-== FinalDataOEMv2.0 Simplified Chinese official version ==-
Serial quantity: oem06026-0636-030552085353
Computer software introduction: The functions and functions in the Super Information Recovery Tool incorporate: support for FAT16 / 32 and NTFS, restore entirely deleted information and directories, restore the principle boot sector and FAT table damaged and lost information, restore the speedy formatted difficult disk and floppy disk Information, recover information destroyed by CIH, recover lost information from hard disk harm, remotely control information recovery via the network, etc.
Compared with the enterprise version, OEM lacks the functions of 'office file recovery' and 'e-mail recovery', the other individuals will be the similar.
Note: Data recovery computer software is frequently deleted, formatted, and data destroyed by viruses. Frequently, information might be recovered by way of this application to lower unnecessary losses. Today's exceptionally powerful hard disk data recovery tool, when the really hard disk boot sector is totally destroyed, plus the basic tool can't even find the challenging disk, you could use it to easily restore the difficult disk data. A further benefit is the fact that it doesn't create towards the difficult disk when recovering Something. The ideal challenging drive information recovery tool
FinalDatav.2.0 serial quantity: NTC62547-0948-020952141825
3. 'PhotoRecoveryforDigitalMedia3.0.six.2' devoted, free of charge of charge, English
http://download.pchome.net/design/digipic/17654.html
Function: It accidentally deletes the photographs taken inside the digital camera. It doesn't matter. With PhotoRecoveryforDigitalMedia, it might restore the digital camera photos accidentally deleted, providing you a medicine for regret.
four. 'EasyPhotoRecoveryV1.2Build308_Recover Deleted Photos on Memory Card_Green Chinese Version'
Download: http://www.xdowns.com/soft/6/99/2006/Soft_32877.html
Function: EasyPhotoRecovery can very easily recover the deleted pictures on the memory card. It supports CompactFlash, SD, MMC, memory stick and so on. The plan has been cracked without the need of functional limitations!
1. Test circumstances
CF card (WINWARD) —128MbSONY original memory stick—32Mb Jinshengyi USB6 in 1 card reader Gigabyte KT4400 motherboard AMD1700 + CPU512MbDDR memory, operating system is WIN2000.
A total of 4 usually employed information recovery softwares had been selected for the experiment. The method is to take a image first, so that you'll find some picture files in the memory card, and after that copy it to a directory as a typical for comparison; then delete the image (or Format in the camera), and after that use several computer software to restore, verify the recovery effect, the comfort of operation, the time applied, and so on.
2. Brief introduction of precise test
2-1, BadCopyproV3.71 Chinese version (size 778Kb)
The installation and registration are regular, you'll be able to use the registration code offered by the download to register, and its operating interface is shown inside the figure under.
Attributes: It could recover data from a number of storage media including floppy disks, CD-ROMs, really hard disks, memory cards, etc. The operation is easy, and also you can start off operating according to the prompts. You are able to opt for the file format when recovering the memory card of the digital camera. The software functions in a complete sector scan mode, after which the file to be restored along with the storage path will have to be chosen prior to the recovered file is officially saved. It could recover all the files on the memory card-the sum on the earlier occasions: As an example, the 128Mb card has 200 photos before, and then formatted, and took an additional 20 images. When the resolution may be the very same prior to and just after, then you can change the final one 20 sheets and 180 sheets (around) in the earlier 200 sheets are restored.
test outcomes:
1. 128MbCF card, formatted after the previous photo, 19 pictures had been taken, deleted and restored, shared 16 minutes, a total of 175 recovered, which includes the final 19, all photographs might be displayed typically.
two. 32Mb memory stick, the last file is 19, 23 files have been restored, two of them can't be displayed typically (the image is only the upper half), and also the shared time is 6 minutes.
All data recovery is stored within the specified folder, and will not be written to the memory card. The recovered file name is: File ###. JPG.
The above approaches are applicable to deleted and formatted memory cards.
2-2 、 EasyRecoveryV6.0 Chinese version
This is a full-featured disk tool application which can execute disk diagnosis, information repair, file repair, mail repair, and so on., and its operating interface is shown within the figure below.
Use the 'Find and restore deleted files' or 'Restore devoid of relying on any file program structure information' (just after formatting the memory card) solution for the memory card. The latter needs to select the information format and scan it rapidly after picking the drive letter The folder around the card (the name will be the identical because the card) along with the file name, file size, and time in it, and then choose the file to become restored to restore. The exceptional function of this computer software is that it runs extremely rapid. Taking SONY32Mb memory stick as an instance, it took only 90 seconds to recover 23 files. The recovered file is SC0 ###. JPG is named and stored inside the specified folder. There are 4 troubles with the recovered files, two are only the upper aspect (exact same as 2-1), and two can't be opened.
2-3 、 PHOTORECOVERYV2.0 Chinese version demo version
This can be a easy and easy-to-use data recovery software program. Its interface is intuitive and straightforward, and the operation might be completed within a handful of actions: initial select the drive letter and the folder exactly where the data is usually to be restored, click Start off to swiftly restore, and it runs The interface is shown below.
The difference using the above software is the fact that in addition, it displays thumbnails synchronously. disappeared sd card disappeared file recovery recovers 23 files in only 1 minute and 55 seconds, and certainly one of them is damaged. Using a 128MbCF card, it took only 6 minutes and ten seconds to restore 175 files (far more than 10 minutes quicker than BadCopypro), and all pictures is usually displayed generally. Nevertheless it is often a pity that the demo version is at the moment utilized and cannot store the recovered data.
The application also visually displays info which include the capacity of your memory card, the partition size, along with the variety of recovered files within the lower left corner with the interface. The recovered information is named 'Image # .JPG'.
2-4 、 AboutmediaRECOVERV2.two.two.4 English version
This is also a graphical interface computer software, the running interface is shown under.
The usage of the software program is similar to PHOTORECOVERY. First choose the drive letter in the memory card as well as the storage folder from the recovery file, and then start out scanning and recovery. It requires a lengthy time and errors. This version cannot be employed commonly.
three. Summary
By way of experiments, it may be noticed that the files inside the memory card is usually entirely recovered immediately after accidental deletion or formatting. The above 4 software can total the recovery operate, plus the functioning approaches are similar, all of which scan the memory card sectors 1st. Just after that, save the recovered files in the designated folder from the difficult disk, and no a lot more files are written to the memory card, so this recovery is secure and will not bring about damage towards the memory card (but BadCopypro computer software demands a lengthy time for you to the card Scan, it really is suggested to make use of significantly less). But the recovery time of every single software program is very diverse. For the 128MbCF card, the lengthy one took 16 minutes along with the quick one particular took six minutes. For Diskgetor damaged sd card camera file recovery , beneath the premise of meeting the needs, you'll want to choose a short-time application as a way to enhance efficiency. For that reason, it is advisable to decide on EasyRecoveryV6.0 Chinese version. If you can register, use PHOTORECOVERYV2.0 is also a fantastic choice; and for long-term memory cards , You could use BadCopyproV3.71 Chinese version to execute a sector scan to view if there is certainly a terrible sector, and also you know it.
The above software program, the compatibility of numerous storage is limited for the conditions, only the CF card and SONY memory stick are tested, along with other memory cards for instance SD, SM, MMC, and so forth. are not tested. It really is advised that those who own these memory cards test and report the outcomes .
In the scanning and recovery of the two cards, if the good quality on the card is no challenge, the recovery is usually standard, and if the card is defective, the software may not be capable of repair, such as two files in the 32Mb memory stick, the software program Only half of the photos are displayed for recovery.
Reference address for downloading the above software program:
EasyRecoveryV6.0 Chinese version http://www.skycn.com/soft/2070.html
PHOTORECOVERYV2.0 http://www.ttdown.com/SoftView/SoftView_12855.html
BadCopyproV3.71 Chinese version http://www.gupin.com/soft/358.htm and
http://www.ttdown.com/SoftView/SoftView_3853.html
mediaRECOVERV2.two.2.4 English version http://www.ttdown.com/SoftView/SoftView_17097.html and http://www.onlinedown.net/soft/20285.htm
Every single day site: http: //www.ttdown.com's graphic image bar can come across many software
1. 'DriveRescue'
Download: www.onlinedown.net/soft/7799.htm
Function: DriveRescue is definitely an great and cost-free disk information rescue program, it can restore information deleted or lost on the drive (for instance difficult disk), even if the partition table has been lost or the hard disk has been quickly formatted or encountered system crashes, Retrieve vital file program facts of your drive such as partition table, boot record, FAT, file / directory records, etc. Not surprisingly, it can do practically nothing about physically broken challenging drives. DriveRescue supports FAT12 / 16/32 partitions, Windows complete range of operating systems and dual tough drives.
two. 'FinalDataOEMv2.0 Simplified Chinese Official Version' supports memory cards with more than 512MB http://www.jz5u.com/Codelist/Catalog160/1978.html
-== FinalDataOEMv2.0 Simplified Chinese official version ==-
Serial quantity: oem06026-0636-030552085353
Computer software introduction: The functions and functions in the Super Information Recovery Tool incorporate: support for FAT16 / 32 and NTFS, restore entirely deleted information and directories, restore the principle boot sector and FAT table damaged and lost information, restore the speedy formatted difficult disk and floppy disk Information, recover information destroyed by CIH, recover lost information from hard disk harm, remotely control information recovery via the network, etc.
Compared with the enterprise version, OEM lacks the functions of 'office file recovery' and 'e-mail recovery', the other individuals will be the similar.
Note: Data recovery computer software is frequently deleted, formatted, and data destroyed by viruses. Frequently, information might be recovered by way of this application to lower unnecessary losses. Today's exceptionally powerful hard disk data recovery tool, when the really hard disk boot sector is totally destroyed, plus the basic tool can't even find the challenging disk, you could use it to easily restore the difficult disk data. A further benefit is the fact that it doesn't create towards the difficult disk when recovering Something. The ideal challenging drive information recovery tool
FinalDatav.2.0 serial quantity: NTC62547-0948-020952141825
3. 'PhotoRecoveryforDigitalMedia3.0.six.2' devoted, free of charge of charge, English
http://download.pchome.net/design/digipic/17654.html
Function: It accidentally deletes the photographs taken inside the digital camera. It doesn't matter. With PhotoRecoveryforDigitalMedia, it might restore the digital camera photos accidentally deleted, providing you a medicine for regret.
four. 'EasyPhotoRecoveryV1.2Build308_Recover Deleted Photos on Memory Card_Green Chinese Version'
Download: http://www.xdowns.com/soft/6/99/2006/Soft_32877.html
Function: EasyPhotoRecovery can very easily recover the deleted pictures on the memory card. It supports CompactFlash, SD, MMC, memory stick and so on. The plan has been cracked without the need of functional limitations!
, it will likely be an enormous blow to you, in particular these valuable, unreproducible lenses, which can not be)
SPOILER ALERT!
How does 3dmax make stunning glass vases? Ways to draw a glass vase with curvature in 3dmax? Let's check out the detailed tutorial under. It really is very easy. Mates who need to have it might refer for the following 1. Open the 3DMAX software and uncove
1. Open the 3DMAX computer software and locate the 'star' two-dimensional graphic inside the made menu bar around the right, since we need to add commands to it to complete the desired result. Click and produce a graphic within the window. As shown.
two. Click the graphic we designed, locate its parameters in the modify panel on the proper, and set it up. Of course, you do n’t have to adhere to my parameter settings, you are able to set it to the impact you wish. As shown.
three. Immediately after the parameter setting is completed, we right-click on the graph and choose 'Convert to Editable Spline' inside the menu that appears, in order that we can edit the dot and segment lines with the graph. As shown.
four. Around the correct immediately after turning
Obtain 'line', click the plus sign, and click 'spline' within the drop-down, in order that we can edit the line. As shown within the figure.
5. At this time, we locate the 'outline' outline inside the drop-down parameters, click, then a smaller pattern will seem on the mouse, click the line we produced, and drag, then you definitely will see one more Line, just a little bit distance away from the original line. At this time our outline is ready. As shown.
six. Click the star line, obtain the 'Extrude' extrusion command within the creation command on the right, and set the parameters on the extrusion command under. We are able to see that a two-dimensional figure has been produced into a three-dimensional shape. As shown.
7. Turn off the smaller bulb prior to the 'Extrude' extrusion command. At this time, we are back inside the two-dimensional graphics, or choose 'line' --- 'spli
ne ”, click, and after that discover the line inside the two-dimensional graph, that's, the line that turns red inside the figure, uncover the“ Detach ”separation command within the parameter around the appropriate, and verify the“ copy ”option around the upper and decrease , When clicked, a tiny dialog box will appear, we rename it to 'line' to confirm, so that we can copy and separate our line. As shown inside the figure.
eight. Pick this line renamed to 'line', pay interest not to make a error right here, then add 'Extrude' extrusion command to minimize the extrusion value. As shown.
9. Click the preceding graphic to light up the compact bulb prior to the extrusion command. At this time, we discover that the vase is completed, but it is as well basic. Locate https://www.bing.com within the modify command and make the following settings, which could be set in line with your predicament. As shown.
damaged sd card camera file recovery . This can be pretty wealthy,
The
But we still have to have to add it, also uncover the 'twist' twisting command, and make the following settings, in line with your situation. As shown.
11. The model is full. I added a straightforward material to it, opened the material editor, and dragged a material ball to the object. As shown.
12. Then obtain the 'Vary' material, this wants to become installed separately, not significantly to say here.
13. There is not a great deal to adjust here. The diffuse reflection is gray, the reflection and refraction are adjusted to white, along with the Fresnel reflection could be turned on. As shown.
14. For the impact, I added a ground and added a texture for the ground. Let's see the impact. How quick is it? Such a prevalent flower vase was made by us.
two. Click the graphic we designed, locate its parameters in the modify panel on the proper, and set it up. Of course, you do n’t have to adhere to my parameter settings, you are able to set it to the impact you wish. As shown.
three. Immediately after the parameter setting is completed, we right-click on the graph and choose 'Convert to Editable Spline' inside the menu that appears, in order that we can edit the dot and segment lines with the graph. As shown.
four. Around the correct immediately after turning
Obtain 'line', click the plus sign, and click 'spline' within the drop-down, in order that we can edit the line. As shown within the figure.
5. At this time, we locate the 'outline' outline inside the drop-down parameters, click, then a smaller pattern will seem on the mouse, click the line we produced, and drag, then you definitely will see one more Line, just a little bit distance away from the original line. At this time our outline is ready. As shown.
six. Click the star line, obtain the 'Extrude' extrusion command within the creation command on the right, and set the parameters on the extrusion command under. We are able to see that a two-dimensional figure has been produced into a three-dimensional shape. As shown.
7. Turn off the smaller bulb prior to the 'Extrude' extrusion command. At this time, we are back inside the two-dimensional graphics, or choose 'line' --- 'spli
ne ”, click, and after that discover the line inside the two-dimensional graph, that's, the line that turns red inside the figure, uncover the“ Detach ”separation command within the parameter around the appropriate, and verify the“ copy ”option around the upper and decrease , When clicked, a tiny dialog box will appear, we rename it to 'line' to confirm, so that we can copy and separate our line. As shown inside the figure.
eight. Pick this line renamed to 'line', pay interest not to make a error right here, then add 'Extrude' extrusion command to minimize the extrusion value. As shown.
9. Click the preceding graphic to light up the compact bulb prior to the extrusion command. At this time, we discover that the vase is completed, but it is as well basic. Locate https://www.bing.com within the modify command and make the following settings, which could be set in line with your predicament. As shown.
damaged sd card camera file recovery . This can be pretty wealthy,
The
But we still have to have to add it, also uncover the 'twist' twisting command, and make the following settings, in line with your situation. As shown.
11. The model is full. I added a straightforward material to it, opened the material editor, and dragged a material ball to the object. As shown.
12. Then obtain the 'Vary' material, this wants to become installed separately, not significantly to say here.
13. There is not a great deal to adjust here. The diffuse reflection is gray, the reflection and refraction are adjusted to white, along with the Fresnel reflection could be turned on. As shown.
14. For the impact, I added a ground and added a texture for the ground. Let's see the impact. How quick is it? Such a prevalent flower vase was made by us.

SPOILER ALERT!
Prior to all work is carried out, please initially establish whether or not the difficult disk is broken and the sort of defect, and also the challenging disk challenges normally concentrate around the following two elements:
Physical (drive failure or component failure);
Logic (file system error or data corruption).
Once you might have a clear understanding in the problem on the challenging disk, you may start out to discover the answer. Here are ten tools for hard disk information recovery. They rely on efficiency and effectiveness to stand out from several similar tools. Let us know collectively!
1.TestDisk
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_1' / amp; gt; amp; lt; / pamp; gt;
Download link
The information repair tool TestDisk can repair the boot partition, restore a partition or delete data, copy files from inaccessible components, and easily repair the partition table. This tool can be used for different file formats for instance FAT, exFAT, NTFS and ext2.
Note: TestDisk is bundled having a PhotoRec application. Now, it only requires a few clicks to restore pictures, videos and files. The scanning has been extended beyond the file method, as well as the data blocks (clusters) related to the missing files is usually completely checked.
Whenever you start TestDisk, you are going to be prompted regardless of whether you'll need a log file. You can see a list of partitions that can be chosen. It could assist the application choose the right signature when reading the disk partition. Just before performing the operation, the computer software will prompt you which difficult disk partitions are out there, and then allow you to select.
The operations you'll be able to perform in each partition are as follows:
· Analyze the partition structure to figure out the proper recovery sequence
· Frame for manipulating the disk
· Clear partition table data
· Recovery of boot location
· Classify and copy files
· Carry out recovery of deleted files
· Create partitioned pictures
The way to use TestDisk?
2.EaseUSPartitionMasterFree
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_2' width = '500' height = '199' border = '0' hspace = '0' vspace = ' 0 'title =' 'style =' width: 500px; height: 199px; '/ amp; gt; amp; lt; / pamp; gt;
Download hyperlink
EaseUs is another superior helper for tough disk recovery data. It really is the most beneficial partition manager, you may move, merge and even split the partition. You'll be able to also perform disk conversion, recover deleted or lost partitions, detect partition errors, migrate OS to HDD / SSD, and carry out disk fragmentation. Making use of the EaseUSPartitionMasterFree tool, you could use the menu (top) or the left pane to operate on the chosen partition.
Tips on how to use EaseUs?
three.WinDirStat
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_3' width = '450' height = '450' border = '0' hspace = '0' vspace = ' 0 'title =' 'style =' width: 450px; height: 450px; '/ amp; gt; amp; lt; / pamp; gt;
Download link
WinDirStat is definitely an ideal recovery tool for disk cleaning. It visualizes the data distribution around the disk as well as defines the information varieties that occupy a lot of the space. Just after you begin the application, the tool generates a tree view from the file, and also you can choose the drive for evaluation. By clicking the inner frame with the graph, you are going to be capable of view the file becoming searched in the tree view.
How to use WinDirStart?
four.CloneZilla
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_4' width = '400' height = '563' border = '0' hspace = '0' vspace = ' 0 'title =' 'style =' width: 400px; height: 563px; '/ amp; gt; amp; lt; / pamp; gt;
Download link
This tool for really hard disk recovery is named CloneZilla. In case you must image and clone the hard drive, the very best alternative is CloneZilla. It's an independent tool, and it can also be made use of with Partedmagic. You will find two forms of CloneZilla: CloneZillaLive and CloneZillaSE (server version). The latter is really a Linux-specific tool that may be installed and configured to send mail to numerous consumers over the network. CloneZillaLive can be a Linux-specific bootable distribution location that will clone a single device.
How you can use CloneZilla?
five.OSFMount
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_5' / amp; gt; amp; lt; / pamp; gt;
Download link
OSFMount is often a practical gadget that supports CD image and memory virtual disk creation and mounting. The characteristic of OSFMount is the fact that it may not just load CD pictures, but additionally generate virtual disks in memory. OSFMount also supports the creation of RAM disk partitions, that may be, the capability to divide a place in memory into a virtual tough disk space. This space are going to be very quickly. For applications, databases, browser caches or games that have to study disks at higher speed , This function is extremely critical. The second advantage is safety. The contents on the disk are all in memory, and also the contents will disappear as quickly because the system is turned off.
When you may have began OSFMount, click Flie (File) and choose Mount new virtual disk. Nevertheless, you have to be sure that the 'ReadOnlyDrive' alternative is checked to stop the risk of overwriting data with recently installed pictures.
The best way to use OSFMount?
6.Defraggler
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_6' / amp; gt; amp; lt; / pamp; gt;
Download link
Defraggler can be a lightweight sorting tool, however it can rapidly and effectively organize a disk, folder or perhaps a file. You'll be able to also check the really hard disk for errors, comparable to the Windows CheckDisk command. Defraggler also has the function of 'defragment specified files / folders' like 'WinContig'. That is where it truly is most distinctive. We are able to view the disk fragmentation of a single file in Defraggler. Just after finishing the evaluation, you may use drive mapping to view fragmented files.
How to use Defraggler?
7.SSDLife
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_7' / amp; gt; amp; lt; / pamp; gt;
Download link
SSDLifefree is definitely an SSD inspection tool. The detection tool is a totally free software utilized under Windows method. Employing SSDLifefree, it may detect the usage time of SSD, 'health' data along with other lives; in the event the World-wide-web sends the SSD data towards the designated server, it may also be accessed from the internet Watch the Wise information of SSD.
Note: Each SSD manufacturer has proprietary SSD management software. By way of example, the Intel SSD Toolbox can create overall health status and provide detailed info for the drive.
How to use SSDLife?
eight.Recuva
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_8' width = '450' height = '484' border = '0' hspace = '0' vspace = ' 0 'title =' 'style =' width: 450px; height: 484px; '/ amp; gt; amp; lt; / pamp; gt;
Download link
Recuva (information recovery computer software) is usually a extremely strong data recovery software that supports all operating systems of the Windwos series and supports data recovery on file systems for example NTFS, Fat32, and exFat. Recuva can successfully recover files that have been deleted or formatted by error, and supports files on storage devices which include pc really hard disks, U disks, and mobile hard disks. error sandisk sd card data recovery can conveniently restore the content material you'd like to restore. Naturally, but you do not like to make use of the application below the step-by-step guidance, it is possible to also skip the wizard and use this plan directly.
When employing Recuva, the program will prompt you to start the scan, after which you might want to choose the file form to become recovered from the menu around the proper, and choose the standard with the filtering selection. You'll be able to also use the filtering options to scan distinct elements (add or remove file varieties). You could also enable deep scanning in place of quick reading scanning. It is possible to also modify the viewing mode and manage the overwrite technique to restore information safely.
The way to use Reccuva?
9.HDTune
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_9' / amp; gt; amp; lt; / pamp; gt;
Download hyperlink
HDTune is usually a compact and easy-to-use challenging disk tool software program. Its primary functions consist of challenging disk transmission rate detection, overall health status detection, temperature detection, disk surface scan access time, and CPU usage. Moreover, it might also detect the firmware version, serial quantity, capacity, cache size, and current UltraDMA mode in the challenging disk. While these functions are also available in other software program, it's commendable that this software combines all these functions in one particular, and it can be quite smaller and rapidly, and more importantly, it can be free of charge application and may be applied freely.
Tips on how to use HDTune?
10.Disk2vhd
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_10' / amp; gt; amp; lt; / pamp; gt;
Download hyperlink
It can be easy to work with Disk2vhd to make a virtual difficult disk. Make a virtual disk from a reside machine, a good selection when made use of with MicrosoftVirtualPC and MicrosoftHyper-V. You can quickly simulate a live atmosphere inside the virtual atmosphere to enhance test efficiency, or you can generate a virtual backup for the reside atmosphere for future use.
Disk2vhd is quite basic to utilize. You just really need to enter the file name and place with the VHD file to be saved, specify the volume to become included, after which click 'Create'. You may also create it by way of Disk2vhd's built-in command line alternatives.
The best way to use Disk2vhd?
recover deleted photos from samsung sd card : magezine8, Baidu, SamSmith compilation, please indicate from FreeBuf hackers and geeks (FreeBuf.COM)
Logic (file system error or data corruption).
Once you might have a clear understanding in the problem on the challenging disk, you may start out to discover the answer. Here are ten tools for hard disk information recovery. They rely on efficiency and effectiveness to stand out from several similar tools. Let us know collectively!
1.TestDisk
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_1' / amp; gt; amp; lt; / pamp; gt;
Download link
The information repair tool TestDisk can repair the boot partition, restore a partition or delete data, copy files from inaccessible components, and easily repair the partition table. This tool can be used for different file formats for instance FAT, exFAT, NTFS and ext2.
Note: TestDisk is bundled having a PhotoRec application. Now, it only requires a few clicks to restore pictures, videos and files. The scanning has been extended beyond the file method, as well as the data blocks (clusters) related to the missing files is usually completely checked.
Whenever you start TestDisk, you are going to be prompted regardless of whether you'll need a log file. You can see a list of partitions that can be chosen. It could assist the application choose the right signature when reading the disk partition. Just before performing the operation, the computer software will prompt you which difficult disk partitions are out there, and then allow you to select.
The operations you'll be able to perform in each partition are as follows:
· Analyze the partition structure to figure out the proper recovery sequence
· Frame for manipulating the disk
· Clear partition table data
· Recovery of boot location
· Classify and copy files
· Carry out recovery of deleted files
· Create partitioned pictures
The way to use TestDisk?
2.EaseUSPartitionMasterFree
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_2' width = '500' height = '199' border = '0' hspace = '0' vspace = ' 0 'title =' 'style =' width: 500px; height: 199px; '/ amp; gt; amp; lt; / pamp; gt;
Download hyperlink
EaseUs is another superior helper for tough disk recovery data. It really is the most beneficial partition manager, you may move, merge and even split the partition. You'll be able to also perform disk conversion, recover deleted or lost partitions, detect partition errors, migrate OS to HDD / SSD, and carry out disk fragmentation. Making use of the EaseUSPartitionMasterFree tool, you could use the menu (top) or the left pane to operate on the chosen partition.
Tips on how to use EaseUs?
three.WinDirStat
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_3' width = '450' height = '450' border = '0' hspace = '0' vspace = ' 0 'title =' 'style =' width: 450px; height: 450px; '/ amp; gt; amp; lt; / pamp; gt;
Download link
WinDirStat is definitely an ideal recovery tool for disk cleaning. It visualizes the data distribution around the disk as well as defines the information varieties that occupy a lot of the space. Just after you begin the application, the tool generates a tree view from the file, and also you can choose the drive for evaluation. By clicking the inner frame with the graph, you are going to be capable of view the file becoming searched in the tree view.
How to use WinDirStart?
four.CloneZilla
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_4' width = '400' height = '563' border = '0' hspace = '0' vspace = ' 0 'title =' 'style =' width: 400px; height: 563px; '/ amp; gt; amp; lt; / pamp; gt;
Download link
This tool for really hard disk recovery is named CloneZilla. In case you must image and clone the hard drive, the very best alternative is CloneZilla. It's an independent tool, and it can also be made use of with Partedmagic. You will find two forms of CloneZilla: CloneZillaLive and CloneZillaSE (server version). The latter is really a Linux-specific tool that may be installed and configured to send mail to numerous consumers over the network. CloneZillaLive can be a Linux-specific bootable distribution location that will clone a single device.
How you can use CloneZilla?
five.OSFMount
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_5' / amp; gt; amp; lt; / pamp; gt;
Download link
OSFMount is often a practical gadget that supports CD image and memory virtual disk creation and mounting. The characteristic of OSFMount is the fact that it may not just load CD pictures, but additionally generate virtual disks in memory. OSFMount also supports the creation of RAM disk partitions, that may be, the capability to divide a place in memory into a virtual tough disk space. This space are going to be very quickly. For applications, databases, browser caches or games that have to study disks at higher speed , This function is extremely critical. The second advantage is safety. The contents on the disk are all in memory, and also the contents will disappear as quickly because the system is turned off.
When you may have began OSFMount, click Flie (File) and choose Mount new virtual disk. Nevertheless, you have to be sure that the 'ReadOnlyDrive' alternative is checked to stop the risk of overwriting data with recently installed pictures.
The best way to use OSFMount?
6.Defraggler
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_6' / amp; gt; amp; lt; / pamp; gt;
Download link
Defraggler can be a lightweight sorting tool, however it can rapidly and effectively organize a disk, folder or perhaps a file. You'll be able to also check the really hard disk for errors, comparable to the Windows CheckDisk command. Defraggler also has the function of 'defragment specified files / folders' like 'WinContig'. That is where it truly is most distinctive. We are able to view the disk fragmentation of a single file in Defraggler. Just after finishing the evaluation, you may use drive mapping to view fragmented files.
How to use Defraggler?
7.SSDLife
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_7' / amp; gt; amp; lt; / pamp; gt;
Download link
SSDLifefree is definitely an SSD inspection tool. The detection tool is a totally free software utilized under Windows method. Employing SSDLifefree, it may detect the usage time of SSD, 'health' data along with other lives; in the event the World-wide-web sends the SSD data towards the designated server, it may also be accessed from the internet Watch the Wise information of SSD.
Note: Each SSD manufacturer has proprietary SSD management software. By way of example, the Intel SSD Toolbox can create overall health status and provide detailed info for the drive.
How to use SSDLife?
eight.Recuva
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_8' width = '450' height = '484' border = '0' hspace = '0' vspace = ' 0 'title =' 'style =' width: 450px; height: 484px; '/ amp; gt; amp; lt; / pamp; gt;
Download link
Recuva (information recovery computer software) is usually a extremely strong data recovery software that supports all operating systems of the Windwos series and supports data recovery on file systems for example NTFS, Fat32, and exFat. Recuva can successfully recover files that have been deleted or formatted by error, and supports files on storage devices which include pc really hard disks, U disks, and mobile hard disks. error sandisk sd card data recovery can conveniently restore the content material you'd like to restore. Naturally, but you do not like to make use of the application below the step-by-step guidance, it is possible to also skip the wizard and use this plan directly.
When employing Recuva, the program will prompt you to start the scan, after which you might want to choose the file form to become recovered from the menu around the proper, and choose the standard with the filtering selection. You'll be able to also use the filtering options to scan distinct elements (add or remove file varieties). You could also enable deep scanning in place of quick reading scanning. It is possible to also modify the viewing mode and manage the overwrite technique to restore information safely.
The way to use Reccuva?
9.HDTune
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_9' / amp; gt; amp; lt; / pamp; gt;
Download hyperlink
HDTune is usually a compact and easy-to-use challenging disk tool software program. Its primary functions consist of challenging disk transmission rate detection, overall health status detection, temperature detection, disk surface scan access time, and CPU usage. Moreover, it might also detect the firmware version, serial quantity, capacity, cache size, and current UltraDMA mode in the challenging disk. While these functions are also available in other software program, it's commendable that this software combines all these functions in one particular, and it can be quite smaller and rapidly, and more importantly, it can be free of charge application and may be applied freely.
Tips on how to use HDTune?
10.Disk2vhd
amp; lt; imgsrc = 'http://image93.360doc.com/DownloadImg/2016/01/2516/65030214_10' / amp; gt; amp; lt; / pamp; gt;
Download hyperlink
It can be easy to work with Disk2vhd to make a virtual difficult disk. Make a virtual disk from a reside machine, a good selection when made use of with MicrosoftVirtualPC and MicrosoftHyper-V. You can quickly simulate a live atmosphere inside the virtual atmosphere to enhance test efficiency, or you can generate a virtual backup for the reside atmosphere for future use.
Disk2vhd is quite basic to utilize. You just really need to enter the file name and place with the VHD file to be saved, specify the volume to become included, after which click 'Create'. You may also create it by way of Disk2vhd's built-in command line alternatives.
The best way to use Disk2vhd?
recover deleted photos from samsung sd card : magezine8, Baidu, SamSmith compilation, please indicate from FreeBuf hackers and geeks (FreeBuf.COM)

SPOILER ALERT!
The key question should be asked following the program crashes, since the method cannot get started, in order that the private user data files stored in the program disk can't be study, then copied to other storage media.
You can find approaches to resolve this problem:
1. Insert a bootable U disk boot disk on this laptop or computer, restart the laptop and enter the U disk PE program, uncover the storage path in the user's individual data files on the really hard disk, and after that copy and paste it towards the U disk or other partition of this challenging disk , After which format the really hard disk method partition, namely the C drive, and it's going to return to standard just after reinstalling the method.
2. If it is actually a dual really hard disk laptop, if the other really hard disk has a technique that may be used commonly (if there is certainly no system, you should set up it first), press the DEL crucial when the computer starts to enter the BOOT choice from the BIOS, set this difficult disk Press F10 to save and restart just after the initial begin, and then follow the above measures to copy files.
three. Dismount and mount the really hard disk to a different computer which will run typically. Following bing restarts, refer to the above method to operate it once again.
Finally, it can be advised that when producing individual data files, users should really develop a good habit of saving to other partitions of your challenging disk, to avoid the trouble of program crash and reinstalling the program, file backup, as well as the loss of important individual data files.
1. Insert a bootable U disk boot disk on this laptop or computer, restart the laptop and enter the U disk PE program, uncover the storage path in the user's individual data files on the really hard disk, and after that copy and paste it towards the U disk or other partition of this challenging disk , After which format the really hard disk method partition, namely the C drive, and it's going to return to standard just after reinstalling the method.
2. If it is actually a dual really hard disk laptop, if the other really hard disk has a technique that may be used commonly (if there is certainly no system, you should set up it first), press the DEL crucial when the computer starts to enter the BOOT choice from the BIOS, set this difficult disk Press F10 to save and restart just after the initial begin, and then follow the above measures to copy files.
three. Dismount and mount the really hard disk to a different computer which will run typically. Following bing restarts, refer to the above method to operate it once again.
Finally, it can be advised that when producing individual data files, users should really develop a good habit of saving to other partitions of your challenging disk, to avoid the trouble of program crash and reinstalling the program, file backup, as well as the loss of important individual data files.

SPOILER ALERT!
The present memory card, irrespective of whether it truly is an SD card, a TF card or possibly a mobile phone memory card, has additional or significantly less several difficulties. As opposed to a U disk, the memory card may be repaired with mass product
Many friends have discovered a big circle of repair tools on line that are either deceptive or unable to repair the memory card. The following mass production network compares the current well known memory card repair tools to speak about the positive aspects and disadvantages, and irrespective of whether it might actually repair the memory card. Make a comparative introduction for the challenge.
The following tools is usually downloaded and employed totally free on this web-site, just click on the computer software name.
1. You will find a number of versions of SDFormatter. The newest version is four.0. Just make use of the most up-to-date version!
SDFormatter is usually a memory card repair tool made by Panasonic. He initially created the software for the memory card challenge of Panasonic cameras. Just after trial production network, it can not simply format and repair Panasonic sd memory cards, but in addition any The memory card is formatted and repaired, such as TF card, mmc card, etc. Regardless of what brand you will be, it can be repaired. His principle is actually based on low-level formatting, which can generally solve the problem that the memory card cannot be opened. Card information error, mobile phone memory card can not be read, and so on. Unique focus is the fact that this tool is advised to insert the memory card in to the card reader and then use it to format and repair it is actually superior. Buddies in the memory card difficulty will be the first to utilize this tool Then, if it appears: the memory card is within the write-protected state, and also you are certain that your TF to SD card sleeve is not dialed to the write-protected position, then this tool will be useless.
two. AutoFormat
AutoFormat is actually a memory card repair tool from Transcend. This tool is entirely a memory card repair tool created for Transcend's personal SD card TF card and also other items. It can also repair any brand of memory card. Of course. For those who are a Transcend memory card, the possibility of thriving repair is a great deal higher, so long as that you are a genuine memory card of other brands, it may be repaired effectively. Following the repair, it may be made use of normally. Editors commonly use the SDFormatter to repair the unsuccessful initial and after that use this tool, which can frequently be solved.
3. Toshiba SD Memory Card Format
Toshiba's memory card formatting repair tool developed by Toshiba was initially utilized for the repair of Toshiba's own Toshiba SD / TF card, nevertheless it can also repair other brands of memory cards. Its principle is equivalent to Panasonic's memory. The card repair tool also needs to turn off the write protection switch. In the event the above two tools are not functioning, you can also try this.
four. Mformat Universal Memory Card Repair and Formatting Tool
This tool is somewhat old, nevertheless it is certainly the only universal low-level formatting tool. It can not simply repair memory cards, but additionally repair U disks and also other devices. This tool is often the ultimate use when the above tools usually are not readily available for mass production networks. Weapon, if it can not support, it's truly not saved. Either the harm is as well serious, or there are also quite a few bad blocks within the cottage junk memory card that can't be repaired. If this can be the case, there is no regret.
to sum up:
In brief, the memory card is broken or it can be repaired. Some friends usually ask 360 and Kingston if there is a memory card repair tool. It truly is clearly said that there isn't any tool at present. We ca n’t do it with out the official. In short, there have to be an issue using the memory card. Try and recover the data. The memory card info rmation recovery software program can use Transcend's RecovRxTool or EasyRecoveryPro6.22 tool. Immediately after recovering the data and then repairing the memory card, there isn't any loss. Of course, if there is absolutely no solution to recover, try and repair the memory card. It is going to operate nicely within the future.
All of the above strategies are computer software repairs, that is certainly, soft repairs. Should you have software, you have challenging. Repairing it in the hardware level just isn't something that we laymen can do. If you have data, you could possibly attempt a luck at a specialty shop to restore the data, but As outlined by encounter, the possibility of recovering the information of the memory card is unlikely, so everyone's significant information should be placed in, by way of example, a mobile hard disk or maybe a personal computer to make a backup. Create https://www.pcworld.com/ , the issue about memory card repair is introduced right here, you'll be able to point it out in the comments under.
The following tools is usually downloaded and employed totally free on this web-site, just click on the computer software name.
1. You will find a number of versions of SDFormatter. The newest version is four.0. Just make use of the most up-to-date version!
SDFormatter is usually a memory card repair tool made by Panasonic. He initially created the software for the memory card challenge of Panasonic cameras. Just after trial production network, it can not simply format and repair Panasonic sd memory cards, but in addition any The memory card is formatted and repaired, such as TF card, mmc card, etc. Regardless of what brand you will be, it can be repaired. His principle is actually based on low-level formatting, which can generally solve the problem that the memory card cannot be opened. Card information error, mobile phone memory card can not be read, and so on. Unique focus is the fact that this tool is advised to insert the memory card in to the card reader and then use it to format and repair it is actually superior. Buddies in the memory card difficulty will be the first to utilize this tool Then, if it appears: the memory card is within the write-protected state, and also you are certain that your TF to SD card sleeve is not dialed to the write-protected position, then this tool will be useless.
two. AutoFormat
AutoFormat is actually a memory card repair tool from Transcend. This tool is entirely a memory card repair tool created for Transcend's personal SD card TF card and also other items. It can also repair any brand of memory card. Of course. For those who are a Transcend memory card, the possibility of thriving repair is a great deal higher, so long as that you are a genuine memory card of other brands, it may be repaired effectively. Following the repair, it may be made use of normally. Editors commonly use the SDFormatter to repair the unsuccessful initial and after that use this tool, which can frequently be solved.
3. Toshiba SD Memory Card Format
Toshiba's memory card formatting repair tool developed by Toshiba was initially utilized for the repair of Toshiba's own Toshiba SD / TF card, nevertheless it can also repair other brands of memory cards. Its principle is equivalent to Panasonic's memory. The card repair tool also needs to turn off the write protection switch. In the event the above two tools are not functioning, you can also try this.
four. Mformat Universal Memory Card Repair and Formatting Tool
This tool is somewhat old, nevertheless it is certainly the only universal low-level formatting tool. It can not simply repair memory cards, but additionally repair U disks and also other devices. This tool is often the ultimate use when the above tools usually are not readily available for mass production networks. Weapon, if it can not support, it's truly not saved. Either the harm is as well serious, or there are also quite a few bad blocks within the cottage junk memory card that can't be repaired. If this can be the case, there is no regret.
to sum up:
In brief, the memory card is broken or it can be repaired. Some friends usually ask 360 and Kingston if there is a memory card repair tool. It truly is clearly said that there isn't any tool at present. We ca n’t do it with out the official. In short, there have to be an issue using the memory card. Try and recover the data. The memory card info rmation recovery software program can use Transcend's RecovRxTool or EasyRecoveryPro6.22 tool. Immediately after recovering the data and then repairing the memory card, there isn't any loss. Of course, if there is absolutely no solution to recover, try and repair the memory card. It is going to operate nicely within the future.
All of the above strategies are computer software repairs, that is certainly, soft repairs. Should you have software, you have challenging. Repairing it in the hardware level just isn't something that we laymen can do. If you have data, you could possibly attempt a luck at a specialty shop to restore the data, but As outlined by encounter, the possibility of recovering the information of the memory card is unlikely, so everyone's significant information should be placed in, by way of example, a mobile hard disk or maybe a personal computer to make a backup. Create https://www.pcworld.com/ , the issue about memory card repair is introduced right here, you'll be able to point it out in the comments under.

1. In the event you pick the flash, the publisher gives a flash address, put the mouse around the flash address, click the correct mouse button, within the pop-up dialog box, click Save Target As (A), choose the one particular you wish to save Tough drive
2. not detected canon sd card data recovery and set up Thunder 5, choose the flash to save, put the mouse around the flash, wait a number of seconds, this icon will seem, click it to download the flash.
three. Download and install the Baidu toolbar, location the mouse around the flash, and two small icons will appear. Around the right, click the full-screen viewing icon, and on the left, click the direct save flash icon. Right after using go to , the download function of Thunder 5 failed.
three. Download and install the Baidu toolbar, location the mouse around the flash, and two small icons will appear. Around the right, click the full-screen viewing icon, and on the left, click the direct save flash icon. Right after using go to , the download function of Thunder 5 failed.
, choose the one particular you wish to save Tough drive)